Live run view
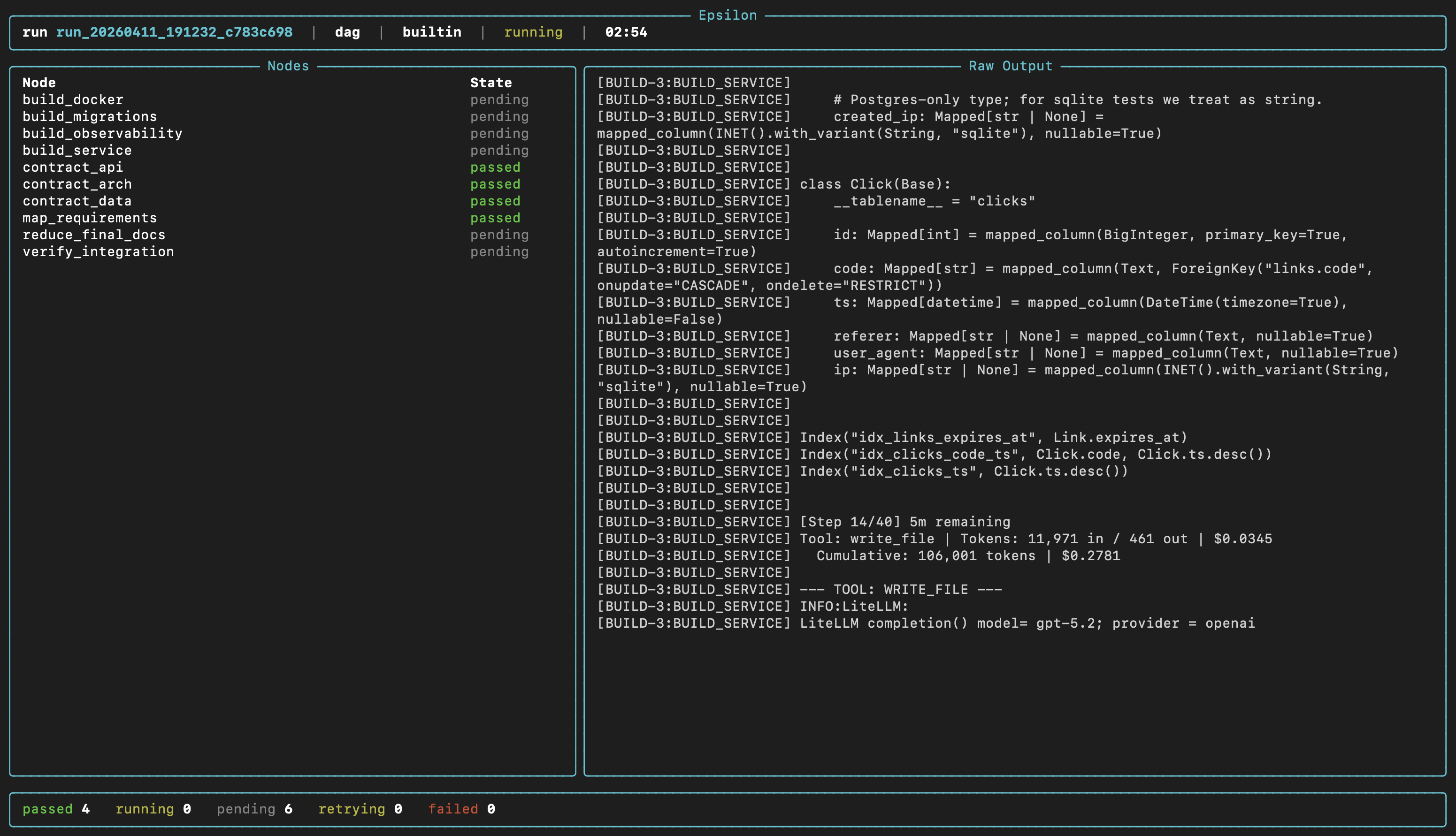
Your agent already works. The hard part is running it again tomorrow with different inputs, splitting work across steps, and not losing the outputs. Epsilon is the orchestration layer you stop rebuilding.
# create a run $ epsilon runs create --topology dag \ --task "Build a URL shortener service" run_id: r-4f8a2c topology: dag status: running # use your own implementation $ epsilon runs create --topology dag \ --task "Process dataset" \ --implementation python:my_agent.py:run # inspect results $ epsilon runs get r-4f8a2c $ epsilon artifacts list r-4f8a2c
Epsilon runs entirely in your environment. There is no hosted service, no API proxy, no telemetry. Your model keys stay on your machines. Your data never leaves. You are not renting access to someone else's platform — you own the software.
Epsilon is a tool you install and run, not a service you depend on. If you stop using it tomorrow, your code, your data, and your workflows are still yours. Nothing is held hostage.
Every run executes on your infrastructure. There is no cloud component, no external API call from Epsilon itself. The only network traffic is between you and whatever model provider you choose.
You pay once for the license. Run as many workflows as you want, with as many agents as you want, on as many machines as you want. There is no per-run cost, no metering, no surprises.
You already have something that works — a LangChain agent, a Python script, a function that calls an API. Epsilon does not replace it. It gives you the infrastructure around it: runs you can replay, workspaces you can inspect, and topologies that coordinate multiple steps without you writing the coordination logic.
Your own agent, script, or deterministic function. Your model keys and infrastructure. Or just use the built-in Epsilon agent. The orchestration layer does not care what runs inside it — if it can read a task and write a file, it works.
Runs, topology execution, shared workspaces, parallel steps, staged workflows, retries, QA loops, artifacts, logs, and summaries. Everything between "I have an agent" and "I have a repeatable workflow."
Every team that gets past the prototype phase builds the same infrastructure: a way to decompose tasks, run them in parallel, collect outputs, handle failures, and record what happened. Then they maintain it. Then they rebuild it when the requirements change. Epsilon is that infrastructure, already built, so you can focus on the work that actually matters.
Every run is recorded — config, logs, artifacts, status. You can inspect what happened, replay it with different parameters, or hand the results to someone else. No more "it worked on my machine."
When a step fails, Epsilon knows which step, why, and what depends on it. QA loops catch errors automatically. Fix cycles retry only what broke. You stop debugging orchestration and start debugging your actual problem.
Change your agent, your model, or your topology without touching the orchestration layer. The same run interface works whether you are using the built-in agent, a LangChain adapter, or a shell script.
Epsilon is built for workflows where some steps are agents, some are function calls, and the coordination between them is the hard part.
Combine CRM data, firmographic APIs, and agent research into structured lead briefs. Mix deterministic lookups with LLM-powered analysis in the same workflow.
Search the web, scrape sources, cross-reference findings, and synthesize everything into a structured deliverable. Let agents do the legwork across dozens of sources in parallel.
Decompose a project into components, build them in parallel across agents, run automated QA, and fix failures without restarting the whole job.
Process high volumes of unstructured input — calls, tickets, documents — through a pipeline of transcription, extraction, classification, and routing.
A bundled, runnable demo that ships with Epsilon. Agents extract entities from 100 Hugging Face document clusters in parallel, deterministic reducers detect ambiguity, and a second wave of agents adjudicates only the hard cases. The output is a canonical entity graph with resolved names, types, and relations.
Each topology is a different coordination strategy. Pick the one that matches your workload. Start with dag if you are not sure.
Read the task. Do your work. Write the output. Return a dict. That is the full adapter contract. Works with LangChain, LlamaIndex, or plain Python — anything that can read a string and write a file.
def run(input, **kwargs): task = input["task"] workspace = input["workspace"] # do your work result = my_agent.execute(task) # write output path = os.path.join(workspace, "output.txt") Path(path).write_text(result) return {"status": "success", "summary": "Done"}
LangChain and LlamaIndex are frameworks for building individual agents — they help you chain prompts, tools, and retrievers into a single agent. Epsilon is the layer above that. It orchestrates multiple agents (or functions, or scripts) across a multi-step workflow with shared workspaces, retries, QA loops, and recorded runs. You can use LangChain or LlamaIndex inside Epsilon — there are starter adapters for both.
CrewAI, AutoGen, and similar tools are multi-agent conversation frameworks — they coordinate agents by having them talk to each other. Epsilon coordinates agents through structure: topologies, dependency graphs, shared workspaces, and recorded artifacts. You pick a coordination pattern (dag, pipeline, tree, queue), and Epsilon handles the execution. Your agents don't need to know about each other. They just read a task and write output.
Traditional workflow tools are built for deterministic pipelines — they assume each step produces a predictable output. Epsilon is built for workflows where some steps are LLM agents that produce variable outputs, where QA loops need to validate and retry, and where the next step might depend on what an agent discovered. You can mix deterministic function calls and agent steps in the same workflow. That said, if your workflow is entirely deterministic, those tools are probably a better fit.
No. The built-in agent is there if you want to get started quickly, but Epsilon is designed to work with your own implementation. Write a Python function that reads a task and writes files, or wrap any external process. The adapter contract is intentionally small — read input["task"], write to input["workspace"], return a dict.
Any model accessible through LiteLLM — OpenAI, Anthropic, open-source models via Ollama, Azure, Bedrock, and others. The built-in agent uses LiteLLM under the hood, so you set an environment variable and go. If you bring your own adapter, you can use whatever model or API you want — Epsilon doesn't care what runs inside the adapter.
No. Epsilon runs entirely on your machine. There is no cloud component, no telemetry, no phone-home. The only network traffic is between you and whatever model provider you configure. If you run a local model, nothing leaves your network at all.
Not by default. Epsilon is proprietary software, and public access to the source does not grant rights to use, modify, deploy, or redistribute it. If you're a safety researcher, nonprofit, or academic team, email us about special licensing.
The software keeps working. You own the version you have — it does not expire, phone home, or stop functioning. You just stop receiving new versions. If you want another 12 months of updates, you can purchase a renewal. If you don't, everything you have continues to work indefinitely.
Private licenses for self-hosted deployment. No subscriptions, no usage fees, no hosted lock-in.
Epsilon deployed on your infrastructure, configured for one workflow, verified end to end. You get a working system, not a license and a link to the docs.